그 상품이 잘 팔린 게, 정말 추천 배너 덕분일까
'추천에 올렸더니 더 팔렸다'는 아직 효과가 아니다. 합성 데이터로 진짜 효과를 심어두고, 매칭 통제군으로 되찾아 본다. 그리고 '총량이 그대로니 잠식은 없다'가 왜 틀린 논리인지.
“추천 배너에 올렸더니 그 상품이 더 팔렸어요.” 이런 말을 들으면 나는 일단 한 발 물러선다. 더 팔린 건 맞을 수 있다. 근데 그게 배너 덕분인지는 아직 모른다. 원래 잘 팔릴 상품을 배너에 올렸을 수도 있으니까.
이 글은 그 구분을 어떻게 하는지에 대한 거다. 회사 데이터 대신 합성 데이터로 처음부터 만들어서 보여주려고 한다. 합성 데이터의 좋은 점은 정답을 내가 안다는 거다. 진짜 효과를 직접 심어두고, 분석이 그걸 되찾아 오는지 보면 된다.
코드는 저장소의
scripts/matched_control_demo.py에 있다.numpy만 있으면 그대로 돌아간다.
진짜 효과를 심어두고 시작한다
상황은 이렇다. e-커머스 홈에 ‘MD 추천’ 배너를 새로 달았다. 상품마다 원래 인기도가 다르고, 인기 있는 상품일수록 추천에 뽑힐 확률이 높다. 이게 선택 편향이다. 그리고 배너에 올라가면 기대 판매가 1.5배가 된다 — 이 1.5배가 우리가 심는 진짜 효과다.
import numpy as np
rng = np.random.default_rng(42)
N = 4000
TRUE_MULT = 1.5 # 배너의 진짜 인과 효과 (우리가 심는 값)
BASE_GROWTH = 1.10 # 배너와 무관한 자연 성장
pop = rng.lognormal(1.0, 1.0, N) # 잠재 인기도
pre = rng.poisson(pop) # 배너 전 판매량 (0이 많다)
p_feat = 1 / (1 + np.exp(-(np.log(pop + 1) - 1.6))) # 인기 상품일수록 추천에 뽑힘
featured = rng.random(N) < p_feat
post = rng.poisson(pop * BASE_GROWTH * np.where(featured, TRUE_MULT, 1.0))한 줄만 눈여겨보면 된다. p_feat이 pop(인기도)을 따라 커진다. 추천 노출이 무작위가 아니라는 뜻이고, 뒤에 나올 문제들이 전부 여기서 나온다.
그냥 비교하면 2.8배
노출된 상품 평균, 안 된 상품 평균. 이 둘을 그냥 나눠 보면:
post[featured].mean() / post[~featured].mean() # → 2.8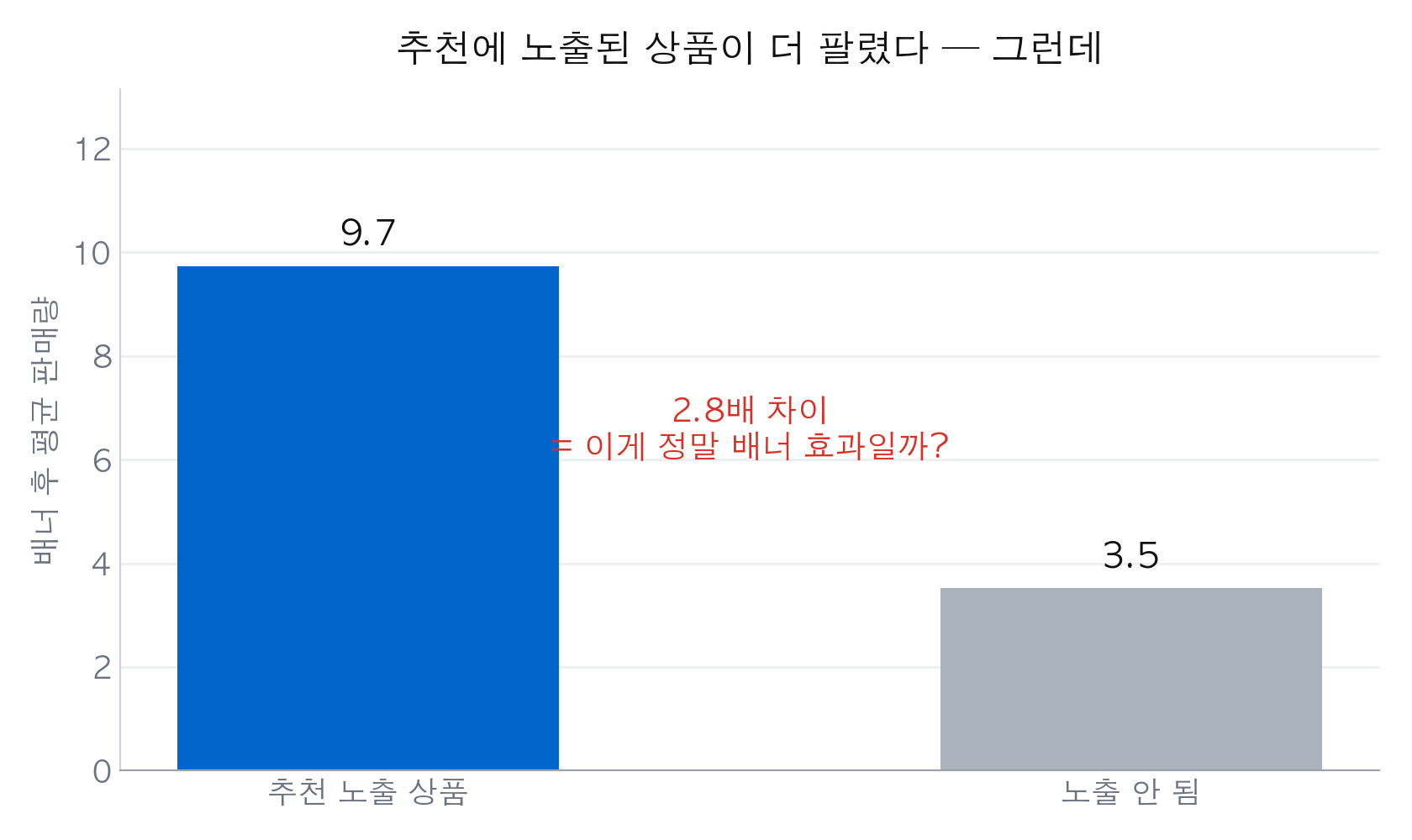
2.8배가 나온다. 우리가 심은 진짜 효과는 1.5배인데 말이다. 왜 부풀려졌냐면 노출군에 애초에 잘 팔리는 상품이 몰려 있어서다. 이 숫자를 그대로 보고서에 쓰면 배너 효과를 거의 두 배로 과장하는 셈이 된다.
출발선을 맞춘다
방법 자체는 단순하다. 배너 전 판매 규모가 비슷한 상품끼리 묶고, 그 안에서 노출된 것과 안 된 것을 비교한다. 출발선을 맞춰놓고 이후가 갈리는지 보는 거다.
mask = pre >= 1
bins = np.quantile(pre[mask], np.linspace(0, 1, 6)) # pre로 5개 층 나누기
# 각 층에서 Σpost/Σpre 로 성장 배수 (작은 pre에서 mean(post/pre)의 상향 편향 회피)여기서 자잘한 문제가 하나 걸린다. 배너 전에 하나도 안 팔린 상품은 “몇 배 늘었나”를 못 잰다. 0에서 시작하면 배수가 안 나오니까. 그래서 두 종류로 나눠서 봤다. 팔리던 상품은 성장 배수로, 안 팔리던 상품은 그냥 이후 판매 횟수로.
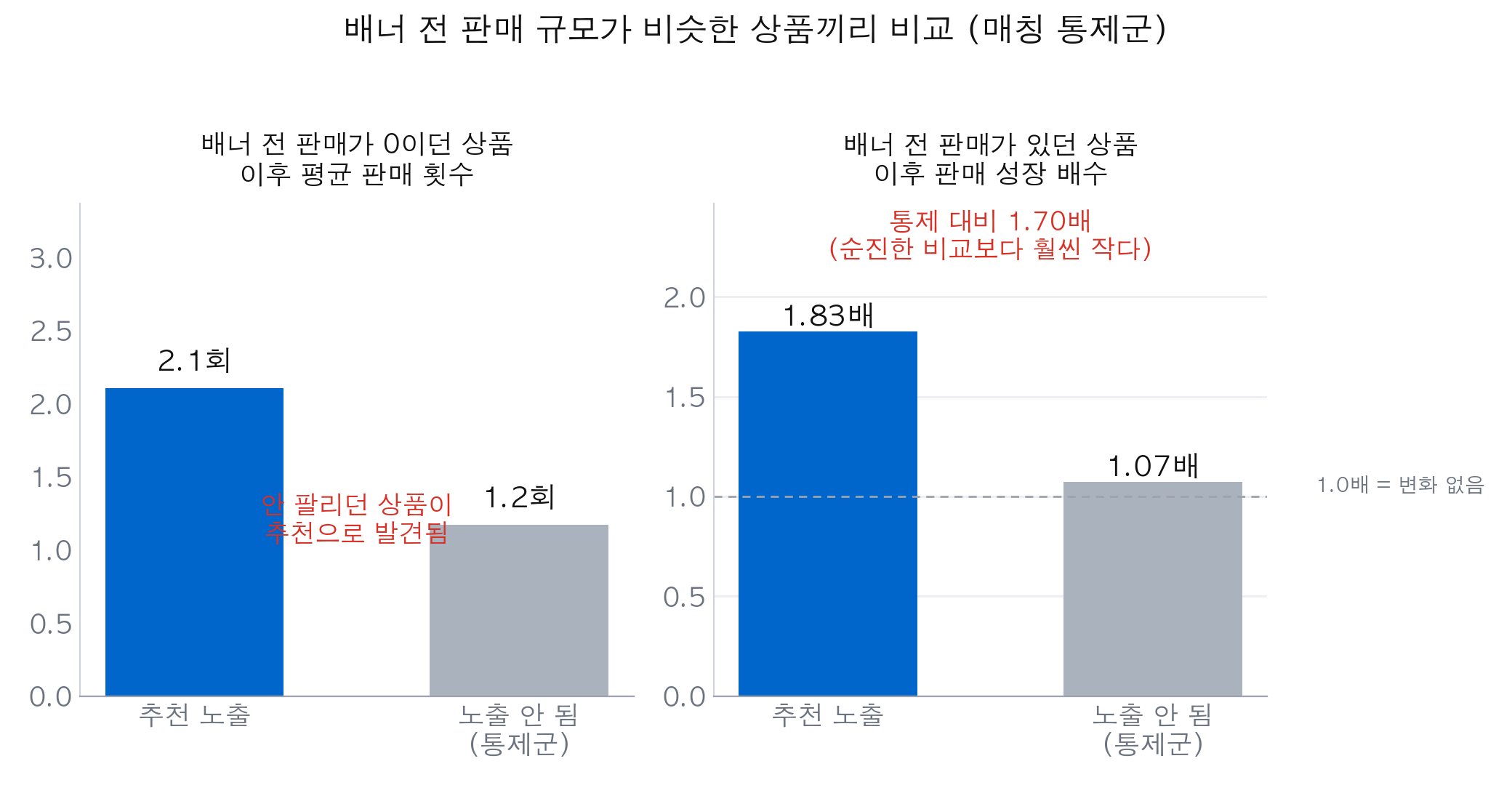
출발선을 맞추니 1.70배로 내려온다. 2.8배였던 게. 심어둔 1.5배에 꽤 가까워졌다. 안 팔리던 쪽(왼쪽 그림)은 배너를 통해 발견된 게 뚜렷하다 — 통제군은 거의 제자리인데 노출군은 몇 번씩 팔렸다.
근데 여기서 정직하게 하나 짚어야 한다. 1.70배는 아직 1.5배보다 높다. 판매량 딱 하나로만 짝을 지었으니 같은 묶음 안에도 편향이 좀 남는다. 매칭은 편향을 줄여주지, 없애주진 않는다. 이걸 “1.5배 정확히 맞혔다”고 하면 그것도 거짓말이다.
이게 더 헷갈린다: “총량이 그대로니 잠식 없음”
효과가 있다고 끝이 아니다. 배너가 다른 상품 팔릴 걸 빼앗아 온 거라면 순효과는 훨씬 작다. 잠식(cannibalization)을 봐야 한다.
여기서 흔히 이렇게 넘어간다. “카테고리 전체 판매량이 배너 전후로 비슷하네? 그럼 잠식은 없는 거지.” 나도 예전에 이렇게 판단한 적이 있는데, 나중에 다시 보고 틀렸다는 걸 알았다. 총량이 평평한 거랑 잠식이 없는 건 다른 얘기다.
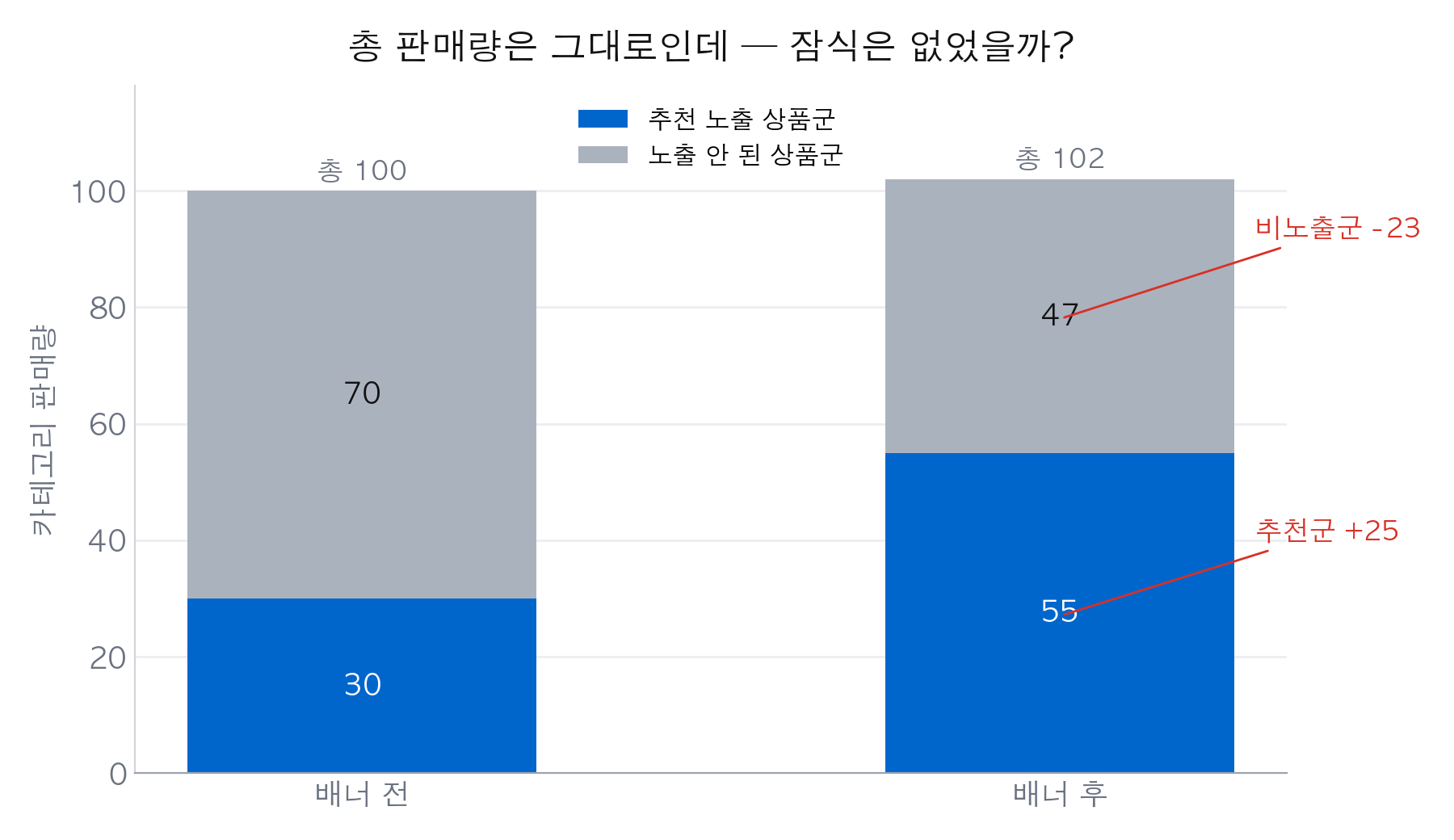
총 판매량은 100에서 102. 거의 안 변했다. 그런데 안을 열어 보면 추천군은 25 늘고 비노출군은 23 줄었다. 배너가 다른 데서 판매를 옮겨온 건데, 합계만 보면 아무 일도 없어 보인다.
잠식을 제대로 보려면 합계 말고 통제군을 봐야 한다. 매칭해 둔 비노출 상품이 배너 후에 가라앉았는지. 안 가라앉았으면 “적어도 이 비교에서는 잠식 신호가 없다”고 말할 수 있다. 물론 이것도 집계 수준 얘기지, 상품 하나하나의 미세한 대체까지 없다는 증명은 아니다.
결국
정리하면 별거 아니다. 두 번 의심하면 된다. 비교하는 두 집단의 출발선이 진짜 같은지, 그리고 “변화 없음” 같은 결론일수록 내가 세운 논리를 한 번 더 뒤집어 보는지.
합성 데이터로 해 보면 이게 왜 중요한지 확 와닿는다. 1.5배를 심어놨는데 2.8배라고 답하는 분석, 잠식이 있는데 없다고 답하는 논리. 실무에선 이런 오답이 정답인 얼굴로 보고서에 실린다. 그걸 걸러내는 건 더 좋은 모델이 아니라, 그냥 한 번 더 의심하는 습관이다.